
Ensaio de Ana Roman, Cassia Hosni e Renata Perim discute a passagem dos vídeos das câmeras de vigilância do dia 8 de janeiro de registro ao documento
Posts tagged IA

From Adversity We Live: Archiving and Digital Media in the Global South
Apresentação realizada por Giselle Beiguelman, Ana G. Magalhães e Ana Avelar no 11o Media Art History Conference. Manizales, maio 2025, discute as particularidades do arquivamento digital sob a ótica do Sul Global

Seminário: ANTAGONISTAS
O Seminário Internacional Antagonistas: Resistências Algorítmicas reúne alguns dos nomes mais interessantes da crítica de mídias, como o designer Vladan Joler, ganhador do Leão de Prata da Bienal de Arquitetura de Veneza, a curadora mexicana Doreen Rios, a pensadora brasileira Larissa Macedo, a ativista e diretora do Olabi, Silvana Bahia, o crítico e professor Daniel Hora, além dos fundadores do Center for Arts, Design, and Social Research, Christopher Bratton e Dalida Benfield.
O que é espaço latente?
Giselle Beiguelman e Renata Perim Uma das funcionalidades da nossa plataforma Meta-Acervos permite visualizar o espaço latente. Você sabe o que é isso? Acompanhe nos slides e teste.

ArtLens do Museu de Arte de Cleveland
Renata Perim O Museu de Arte de Cleveland (CMA) lançou em 2020 uma série de recursos de IA para explorar as obras de domínio público de seu acervo. O Share Your View e o Extend…
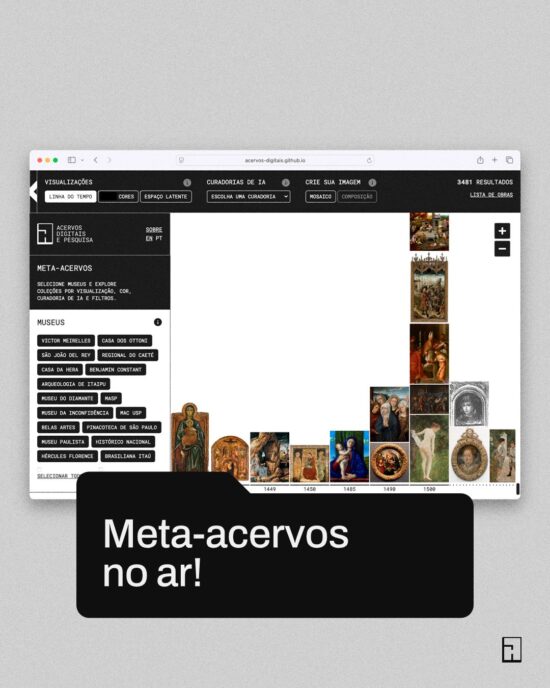
Meta-Acervos no ar!
Meta-acervos é uma plataforma experimental de pesquisa visual que permite buscar e comparar obras de diferentes coleções de arte a partir de suas características formais — como cor, composição e presença de elementos figurativos.
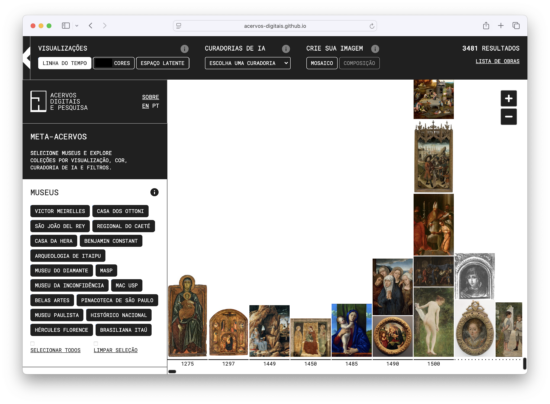
Meta-Acervos: Navegador para Museus em Rede
Meta-acervos é um navegador para museus em rede, criado pelo nosso Projeto Temático Fapesp, que propõe uma metodologia para um sistema de análise, processamento, organização e navegação em acervos abertos de imagens de obras de arte.

Estamos em Obras
Estamos em Obras: Nosso grupo de pesquisa está desenvolvendo um sistema de IA para catalogação das plantas que aparecem em obras de arte de diversos acervos museológicos. O sistema traz um bônus para o público:…

Inteligência artificial e a produção acadêmica
Cássia Hosni Pesquisa da Revista Fapesp aponta levantamento realizado com 5 mil pesquisadores de mais de 70 países. Segundo o artigo publicado na Revista Fapesp, em junho de 2025, para a maioria dos entrevistados, a…

Arquivo inexistente e inteligência artificial
Rian Souza Você já imaginou trabalhadores rurais se beijando ou trabalhadores têxteis se abraçando apaixonadamente? Em ‘Um Arquivo Inexistente’, o artista Felipe Rivas San Martín recria um passado queer na América Latina usando inteligência artificial….

Arquivo de cheiros: “Nose first” explora o patrimônio olfativo
Renata Perim Arquivos digitais oferecem muitas formas de acesso ao patrimônio cultural. Dados e metadados das imagens e textos podem ser pesquisados e analisados por humanos e máquinas, mas essa riqueza de informações frequentemente permanece…

Exposição Arquivo e Memória do 8 de Janeiro
A exposição “Arquivo e Memória do dia 8 de janeiro de 2023” analisa imagens de 33 câmeras do Palácio do Planalto em experimento do Projeto Temático Fapesp Acervos Digitais.

Visão computacional aplicada a arquivos de arquitetura, arte e design
Por Thiago Hersan e Giselle Beiguelman Em colaboração com o projeto Arquigrafia, experimentamos diferentes modelos de Visão Computacional para analisar imagens de um acervo de arquitetura, do qual extraímos dados sobre arte e design, criando…
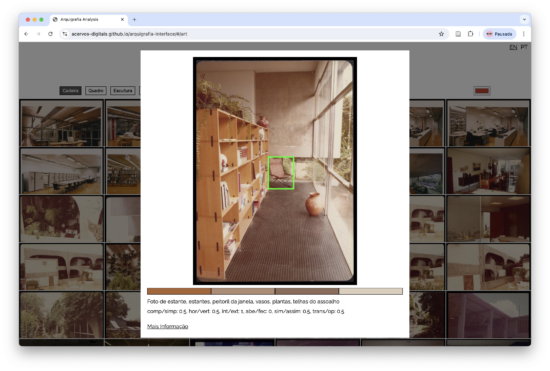
Parceria: Acervos Digitais + Arquigrafia
Hoje, quando se fala em descolonizar as instituições, os lugares de memória, os acervos, isso passa também por criar e inventar formas de ultrapassar as barreiras físicas entre os sistemas Iniciamos uma parceria com o…