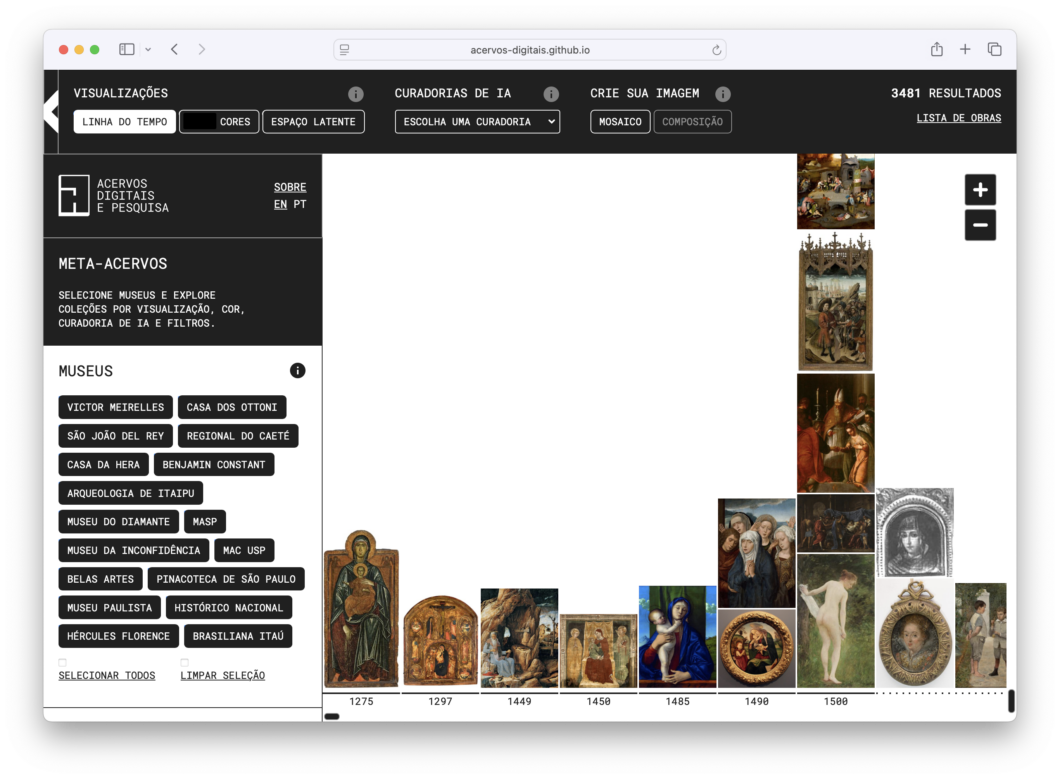
Meta-acervos é um navegador para museus em rede, criado pelo nosso Projeto Temático Fapesp, que propõe uma metodologia para um sistema de análise, processamento, organização e navegação em acervos abertos de imagens de obras de arte.
Neste post apresentamos: os conteúdo que trabalhamos (Coleções e Acervos); os principais aspectos do desenvolvimento tecnológico do projeto (itens 1 a 4); as principais funcionalidades da interface (itens 5 a 7) e um roteiro sobre as diferentes formas de navegar e explorar a plataforma.
Sumário
Coleções e Acervos
Esta primeira versão inclui 4.200 obras provenientes de duas fontes (Wikimedia GLAM project e Brasiliana Museus), que possuem seus arquivos em formatos abertos e com metadados estruturados. Foram incluídos, também, dados selecionados do acervo do MAC-USP, totalizando 17 diferentes museus brasileiros.
Os seguintes acervos foram incluídas nesse estudo:
- Wikimedia GLAM: MASP, Belas Artes, Pinacoteca de São Paulo, Museu Paulista, Museu Histórico Nacional, Instituto Hércules Florence, Coleção Brasiliana Itaú.
- Brasiliana Museus: Museu da Inconfidência, Museu Victor Meirelles, Casa dos Ottoni, Museu de São João Del Rey, Museu Regional do Caeté, Casa da Hera, Museu Casa de Benjamin Constant, Museu de Arqueologia de Itaipu, Museu do Diamante
- MAC-USP
Utilizando as APIs1 disponibilizadas por esses projetos, podemos selecionar, filtrar e agregar conteúdo relevante ao nosso projeto, tais como informações sobre autoria, data de criação, título da obra e técnica. Para esse primeiro protótipo focamos em desenhos e pinturas em coleções de museus brasileiros. Algumas das obras do banco de dados da Wikimedia também incluem informação sobre pessoas, objetos e eventos que estão retratados nos desenhos e pinturas, como na obra Desembarque de Pedro Álvares Cabral em Porto Seguro em 1500, de Oscar Pereira da Silva, pertencente ao acervo do Museu Paulista da USP. Essa informação pode ajudar em organizações, recortes e agrupamentos mais específicos das obras.
Processamento de Imagens
Imagens de cada uma das 4.200 obras foram armazenadas em nosso servidor e processadas usando o seguinte fluxo:
- Redimensionamento: as imagens são redimensionadas para terem tamanhos mais consistentes e padronizados.
- Análise de cores: processo de análise que extrai as 4 cores mais representativas de cada imagem. Esse processo é semelhante à posterização de softwares de edição de imagens, que reduz a quantidade de cores de uma imagem, mas modificado para evitar tons de cinza. Isso é importante porque tons de cinza são cores muito comuns que não servem para diferenciar ou caracterizar elementos específicos de cada imagem.
- Extração de características visuais: usando um modelo multimodal contrastivo, pré-treinado em pares de imagens e textos, extraímos embeddings de alta dimensão para cada uma das imagens das obras. Esse processo de embedding usa técnicas de aprendizagem profunda para representar o conteúdo das imagens usando 1.536 números.
Análise de cores:


Extração de características visuais
A partir de um modelo que entende visão e linguagem ao mesmo tempo (modelo contrastivo), transformamos imagens em vetores (listas de 1.536 números que representam, de forma abstrata, o conteúdo e o estilo de cada imagem). Esse processo, chamado de embedding, utiliza técnicas de aprendizagem profunda para extrair informações visuais complexas, permitindo que as imagens sejam analisadas de maneira automatizada e inteligente.
Esses números representam o conteúdo e estilo de cada imagem. Por exemplo, um desses números pode ter informação sobre a quantidade de pessoas presentes em uma imagem; outro desses números pode representar se as pessoas estão longe ou perto da câmera; e um terceiro pode indicar em que parte da imagem essas pessoas estão. Na prática, o significado dos números desses embeddings é muito mais abstrato e complexo. Geralmente, não é possível saber exatamente o que cada um representa, mas é possível usar o conjunto desses 1.536 números para extrair relações e conexões entre imagens.
Busca por Objetos de Interesse
Depois do processamento e análise inicial que leva em consideração a obra inteira, realizamos uma busca por objetos específicos dentro do conteúdo de cada obra.Essa busca foi feita usando um modelo de vocabulário aberto (OWLv2) que detecta objetos usando uma técnica chamada aprendizagem de zero exemplos. Esse tipo de modelo é capaz de detectar objetos que não estavam presentes nos datasets de treinamento. Isso acontece através de um processo que realiza duas buscas em paralelo: a primeira identifica regiões da imagem que contém coisas que podem ser consideradas “objetos”. Ao mesmo tempo, uma outra busca determina se sub-regiões da imagem contém os objetos que estamos buscando. Em síntese, uma busca é usada para determinar se esses objetos estão presentes e a outra onde esses objetos estão.Usamos o modelo OWLv2 para buscar termos relacionados a fauna e flora: árvores, flores, frutas, grama, palmeiras, cachorros, cavalos, aves, etc.


Problemas
Uma deficiência desse modelo quando usado em obras de arte, é que algumas representações artísticas acabam confundindo o modelo, que erra na classificação de certos animais:

A situação mais problemática nesse caso é que alguns termos para animais também acabam marcando pessoas com certa frequência:

Um modelo mais específico para detectar esses elementos em pinturas poderia ser treinado, mas para este protótipo de Navegação em Acervos, decidimos apenas evitar termos com alta probabilidade de erros.
Agrupamento por Embedding
A última análise que realizamos para permitir a criação de novos recortes desses acervos foi usando um algoritmo de agrupamento automático por embedding.
A representação numérica de 1.536 números do embedding de cada uma das obras do nosso meta-acervo pode ser usada em um processo de agrupamento, ou clustering, para dividir as 4.200 obras em grupos de afinidade visual. Ou seja, pedimos para o algoritmo dividir o acervo em oito grupos, sem saber quais seriam os grupos definidos pela inteligência artificial, mas sabendo que as obras,dentro de cada grupo, teriam características visuais ou temáticas em comum.
É possível olhar as imagens incluídas em cada um dos grupos e verificar que realmente fazem parte de um conjunto com características comuns. Mas, porque o processo separa as obras de acordo com os valores numéricos dos embeddings, não fornece nenhum tipo de descrição para os grupos.

Experimentamos com alguns algoritmos para descrever esses grupos de imagens. Transformar os embeddings das imagens em texto não é algo muito fácil, mas o que podemos fazer é transformar as palavras chaves das descrições das obras da Wikimedia em embeddings, e comparar os embeddings dessas palavras com os embeddings de imagens representativas de cada grupo.

Ao todo foram extraídas mais de 5.000 palavras das descrições das obras. Uma vez feitas as comparações entrea as descrições, definimos oito grupos que chamamos de Curadorias das IAs em nosso experimento. São elas:
- estudos de figuras, esboços
- figuras religiosas, madona e cristo
- pinturas de paisagem
- pinturas de retrato
- figuras abstratas, formas fragmentadas
- retratos formais, figuras históricas
- desenhos arquitetônicos, painéis decorativos
- formas geométricas
Dados Abertos
Todas as informações sobre as obras, tanto a informação original/oficial, quanto a criada através do processamento de visão computacional, foram salvas em arquivos json e estão disponíveis neste repositório.
Interface de navegação
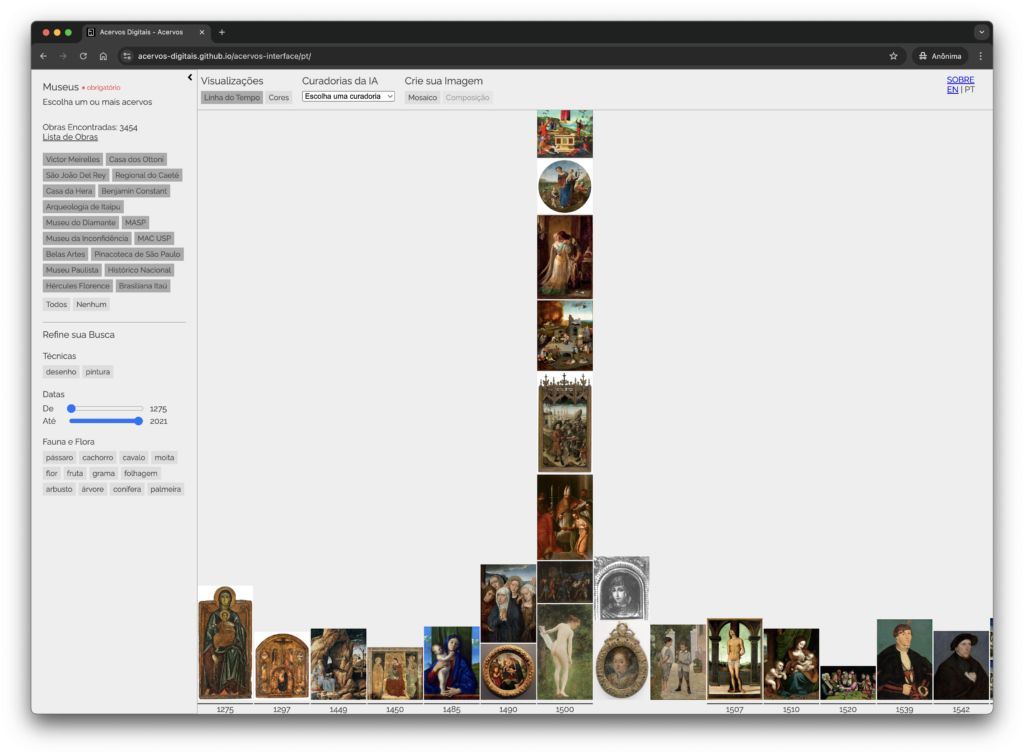
Por fim, criamos uma interface para navegar nos arquivos usando os vetores criados por visão computacional.

Nossa interface inclui filtros para selecionar obras de acordo com o seu acervo, tipo de obra (desenho ou pintura) e ano de criação. Também é possível selecionar obras baseadas nos objetos de fauna e flora encontrados e por agrupamento/embedding.
Disponibilizamos dois tipos de visualizações principais: uma que organiza as obras escolhidas por ordem cronológica de criação, e outra que é capaz de organizar as obras a partir de suas cores representativas. É possível também visualizar o espaço latente entre as obras e navegar em curadorias feitas autonomamente com inteligência artificial.
Crie sua Imagem

Além dessas visualizações interativas por cor e ano de criação, também experimentamos com a criação de visualizações estáticas que chamamos de mosaicos. Essas visualizações não são interativas porque processam um número grande de imagens e necessitam de mais recursos para serem geradas, o que nem sempre é possível dentro de um browser. De qualquer modo, podemos usar a interface para fazer um pedido para nosso servidor que faz o processamento e devolve imagens que podem ser exibidas no browser, junto com uma listagem das obras utilizadas na sua criação, linkadas aos seus acervos originais.
Através desse sistema podemos criar dois tipos diferentes de imagens: que chamamos de Mosaico e Composição. Nas imagens de Mosaicos os objetos de fauna e flora encontrados são disponibilizados de maneira linear ao longo da imagem, e nas imagens de Composição esses mesmos objetos são colocados em posições relativas à sua localização original dentro da obra de arte onde foram encontrados.

Equipe
Coordenação: Giselle Beiguelman
Tecnologia: Thiago Hersan
Revisão: Ana Gonçalves Magalhães, Bruna Keese e Cassia Hosni
Navegue
Conheça o Meta-Acervos, navegador para museus em rede
- API é a sigla para Application Programming Interface, ou em português, Interface de Programação de Aplicações. Uma API designa um conjunto de regras que permite que diferentes softwares “conversem” entre si. ↩︎